0 images
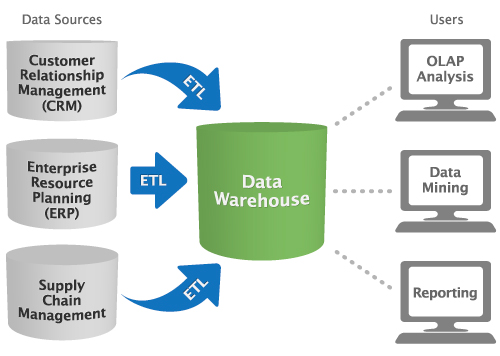
Classical ETL BI Architecture
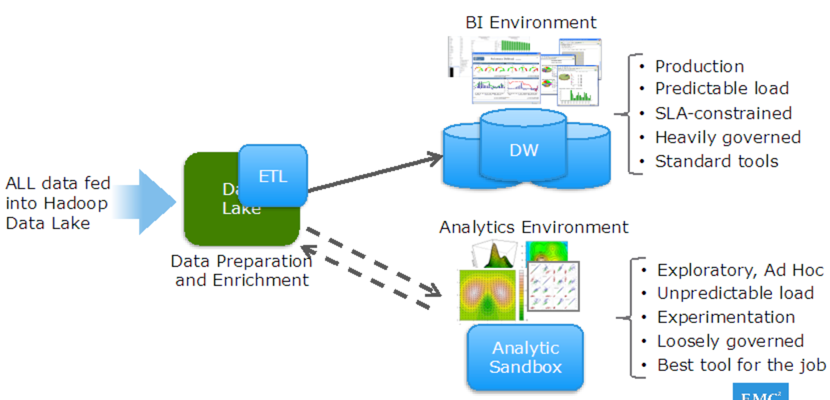
Modern Big Data Analytics Architecture
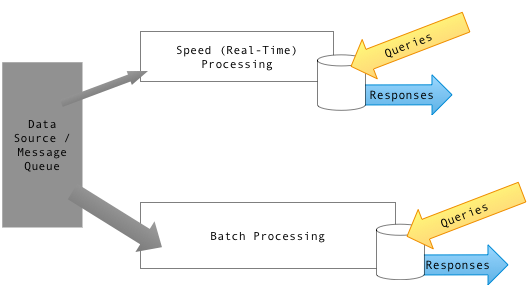
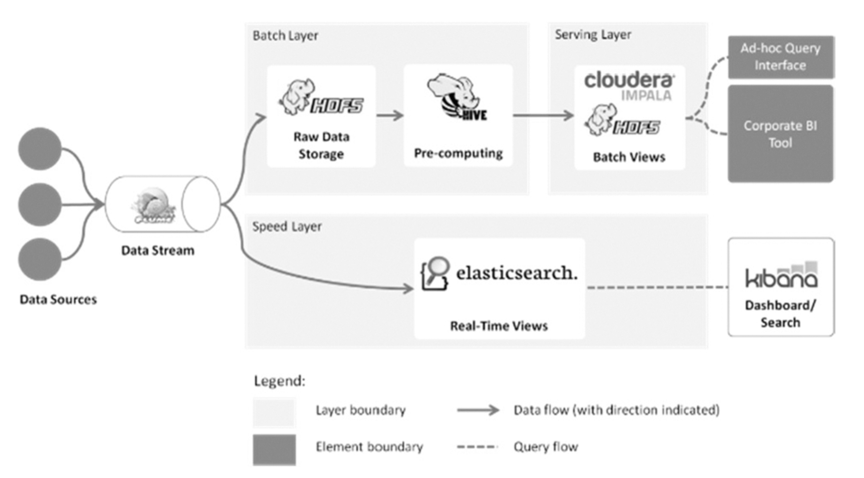
Lambda Architecture
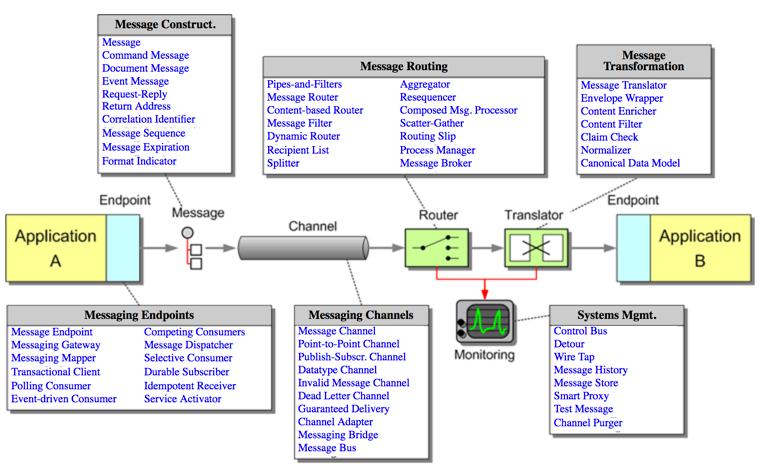
Message Integration Patterns
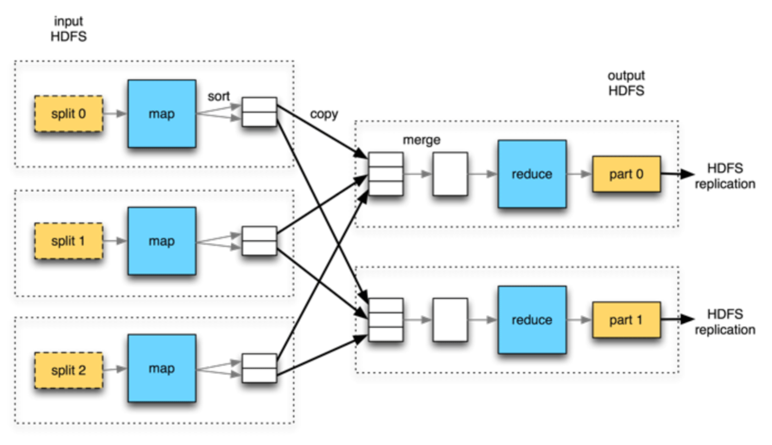
Hadoop MapReduce Illustration
There are two central components to the Hadoop framework.
- First the MapReduce framework is designed to compute large volumes of data in parallel. This requires clustering data across multiple machines.
- A MapReduce task involves two steps – mapping and reducing. The algorithm for MapReduce is not new, but has become popular because of Hadoop.
First a mapping program reads and performs filtering and sorting, such as sorting employees by last name into queues, then a reduce program then acts as an aggregation step, perhaps summarizing names into like names and counting them.MapReduce operates in parallel over many MapReduce nodes.
Mappers and reducers are unaware of each other and operate independently. Next is the Hadoop Distributed File System, or the HDFS is designed to be used by large file, the default file size of an HDFS segment is 64 megabytes.
The HDFS has a transfer rate of 100 megabytes per second, which has a seek time of about 10 milliseconds. It makes use of two daemons called the master and the name node to manage files and maintain their metadata across the cluster.
Hadoop was originally developed from the Google file system and Google MapReduce, being open source, Hadoop is free and usage is covered under the Apache 2.0 license.
One of the unique design features of Hadoop is it works on the principle of moving computation near data rather than the traditional way of transferring data to programs.
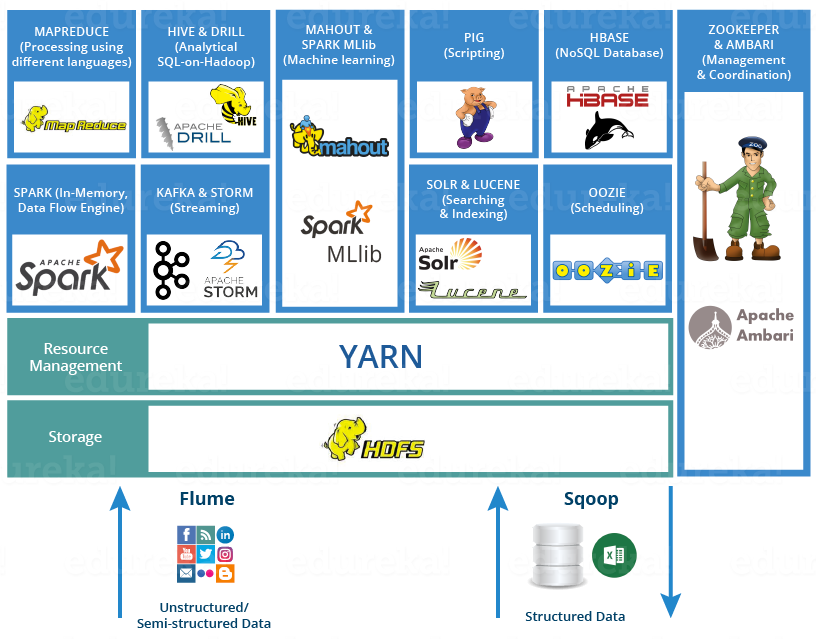
Hadoop Ecosystem
- HDFS -> Hadoop Distributed File System
- YARN -> Yet Another Resource Negotiator
- MapReduce -> Data processing using programming
- Spark -> In-memory Data Processing
- PIG, HIVE-> Data Processing Services using Query (SQL-like)
- HBase -> NoSQL Database
- Mahout, Spark MLlib -> Machine Learning
- Apache Drill -> SQL on Hadoop
- Zookeeper -> Managing Cluster
- Oozie -> Job Scheduling
- Flume, Sqoop -> Data Ingesting Services
- Solr & Lucene -> Searching & Indexing
- Ambari -> Provision, Monitor and Maintain cluster
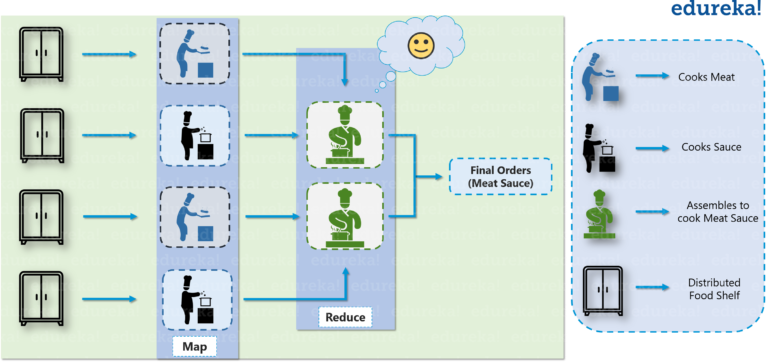
Hadoop Illustration (kitchen)
Example Big Data Architecture
Kafka Architecture
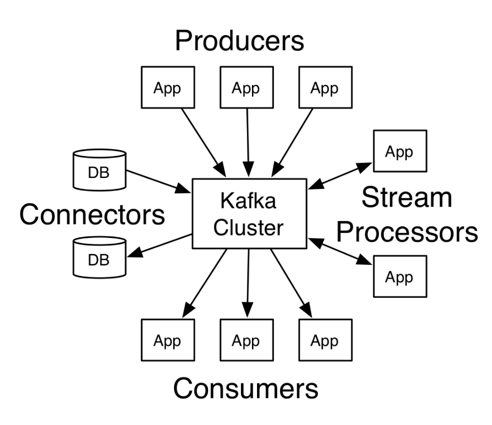
Kafka Primer
Kafka is designed from the ground up to deal with millions of firehose-style events generated in rapid succession. It guarantees low latency, “at-least-once”, delivery of messages to consumers. Kafka also supports retention of data for offline consumers, which means that the data can be processed either in real-time or in offline mode.
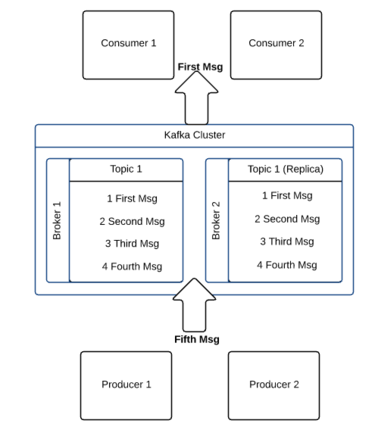
Expanding further on the persistence and retention, Kafka is designed to be a distributed commit log. Much like relational databases, it can provide a durable record of all transactions that can be played back to recover the state of a system. The key thing to understand is that the data is stored durably in an order that can be read deterministically. Due to the distributed design, Kafka provides redundancy, which ensures high availability of data even when one of the servers faces disruption.
This architecture makes Kafka the gateway for all things data. Multiple event sources can concurrently send data to a Kafka cluster, which will reliably gets delivered to multiple destinations.
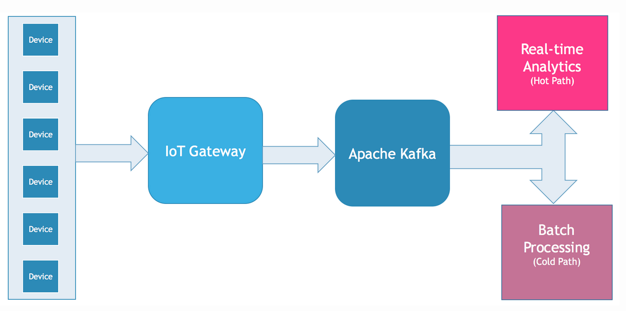
Big Data Messaging with Kafka
Links:
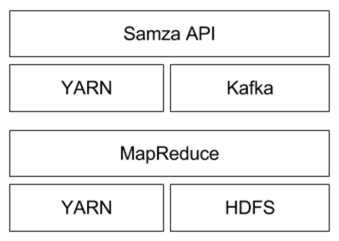
Sazma vs. Hadoop
Samza is made up of three layers:
- A streaming layer.
- An execution layer.
- A processing layer.
Samza provides out of the box support for all three layers.
- Streaming: Kafka
- Execution: YARN
- Processing: Samza API
This architecture follows a similar pattern to Hadoop (which also uses YARN as execution layer, HDFS for storage, and MapReduce as processing API).